ComfyUI学习笔记(一):环境搭建
1.创建基础环境
1 | # 默认安装conda |
2.安装pytorch环境
不同版本的Pytorch安装命令可以从Pytorch安装命令查询得到,我这里安装2.6.0
1 | >> pip install torch==2.6.0 torchvision==0.21.0 torchaudio==2.6.0 --index-url https://download.pytorch.org/whl/cu124 |
最近感觉国内源好像没有官方源快,就直接用官方源吧。
3.安装ComfyUI
1 | # 1.下载源码:默认已装git,由于cuda版本较旧, |
4.启动ComfyUI服务
- (1)启动服务:
1 | # 1.直接启动 |
- (2)访问服务:网页端打开<服务器ip>:10086即可:
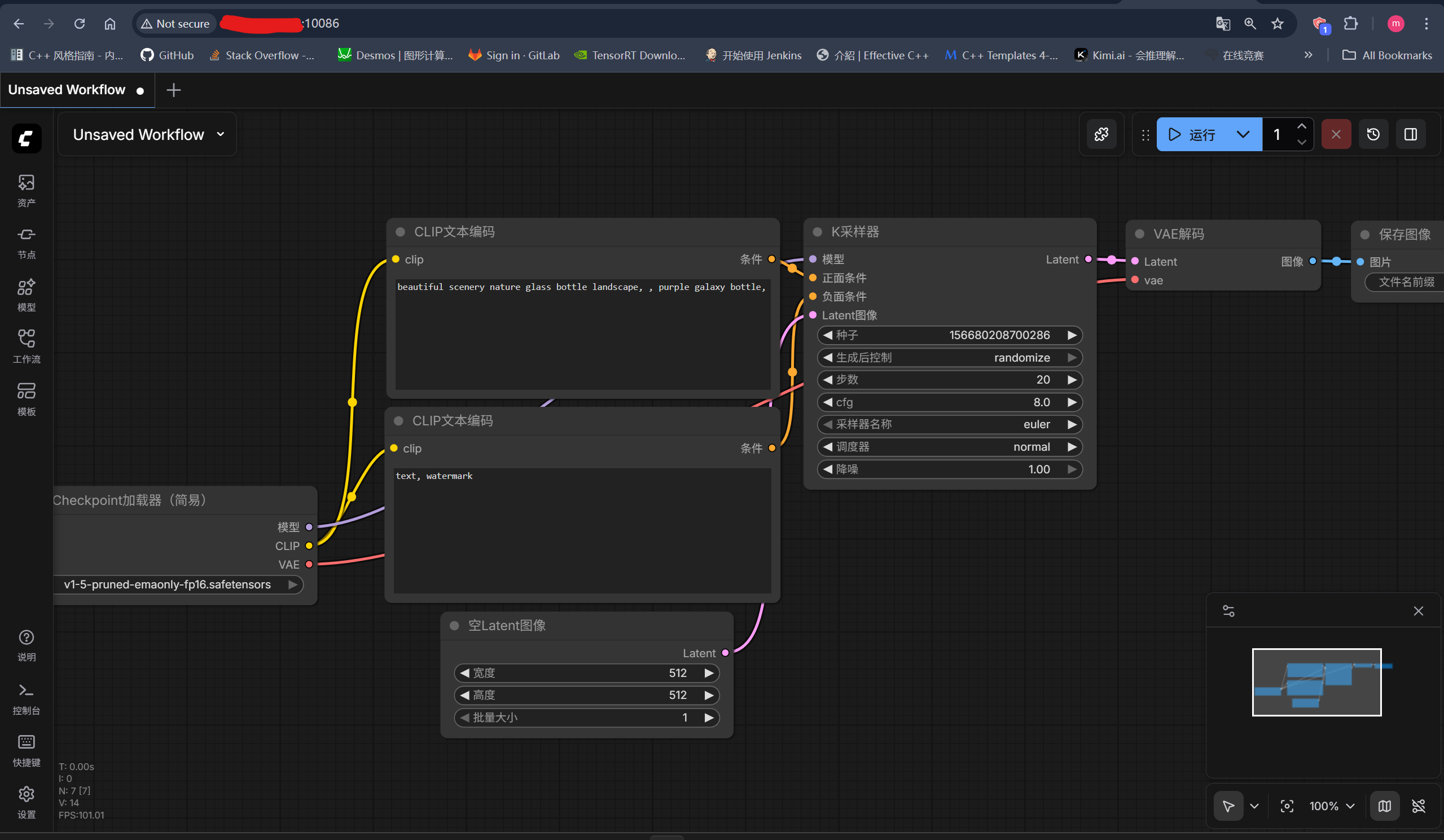
5.文生图工作流
5.1 打开Z-Image-Turbo文生图工作流:
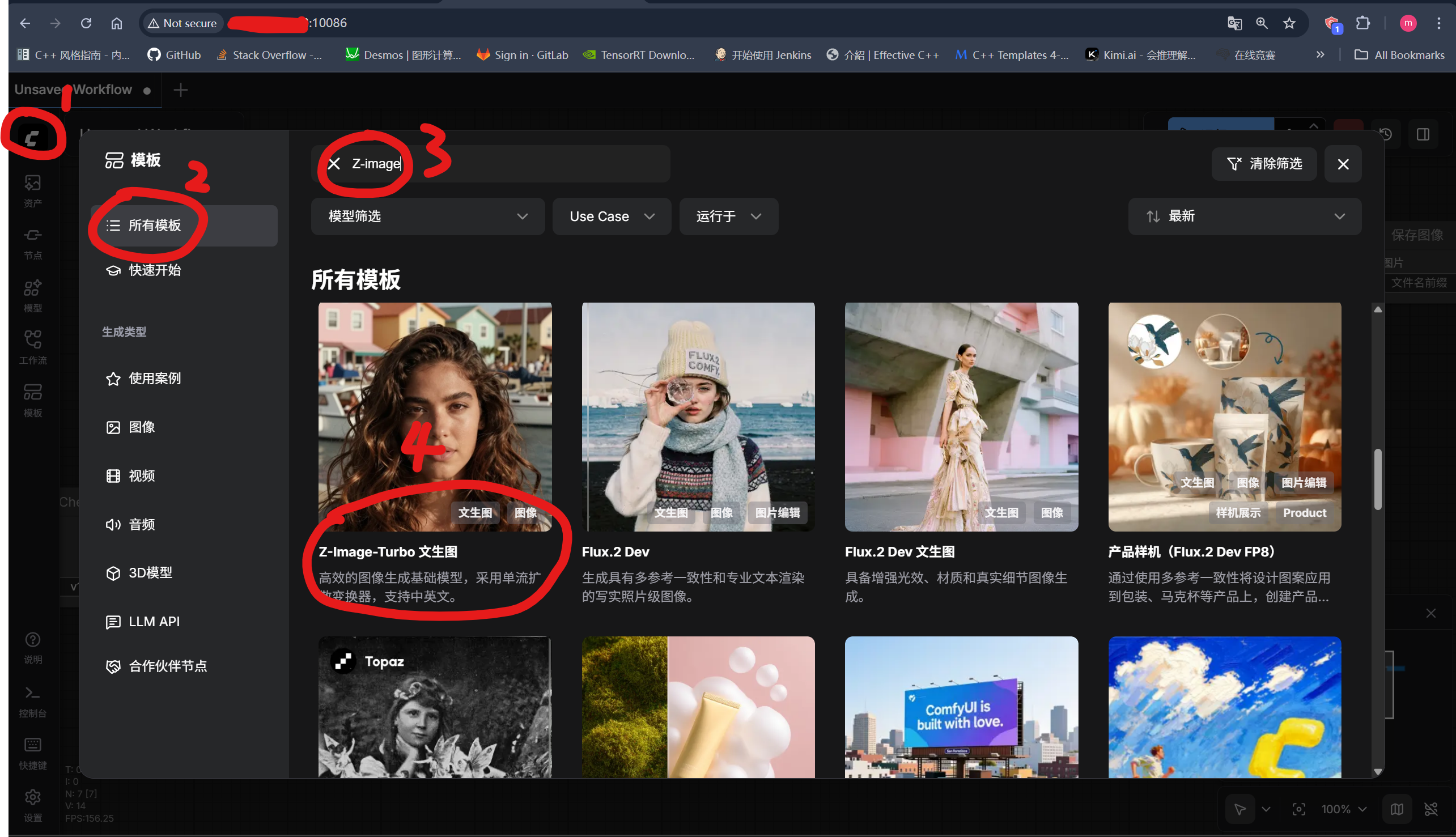
5.2 下载所需模型
- (1)
models/text_encoders/qwen_3_4b.safetensors:8.04GB - (2)
models/vae/ae.safetensors:335.30MB - (3)
models/diffusion_models/z_image_turbo_bf16.safetensors:12.31GB - (4)
models/loras/pixel_art_style_z_image_turbo.safetensors:170.13MB
5.3 直接执行工作流
调整一下提示词后运行,提示词调整为:生成一个红色的苹果,局部出现腐烂
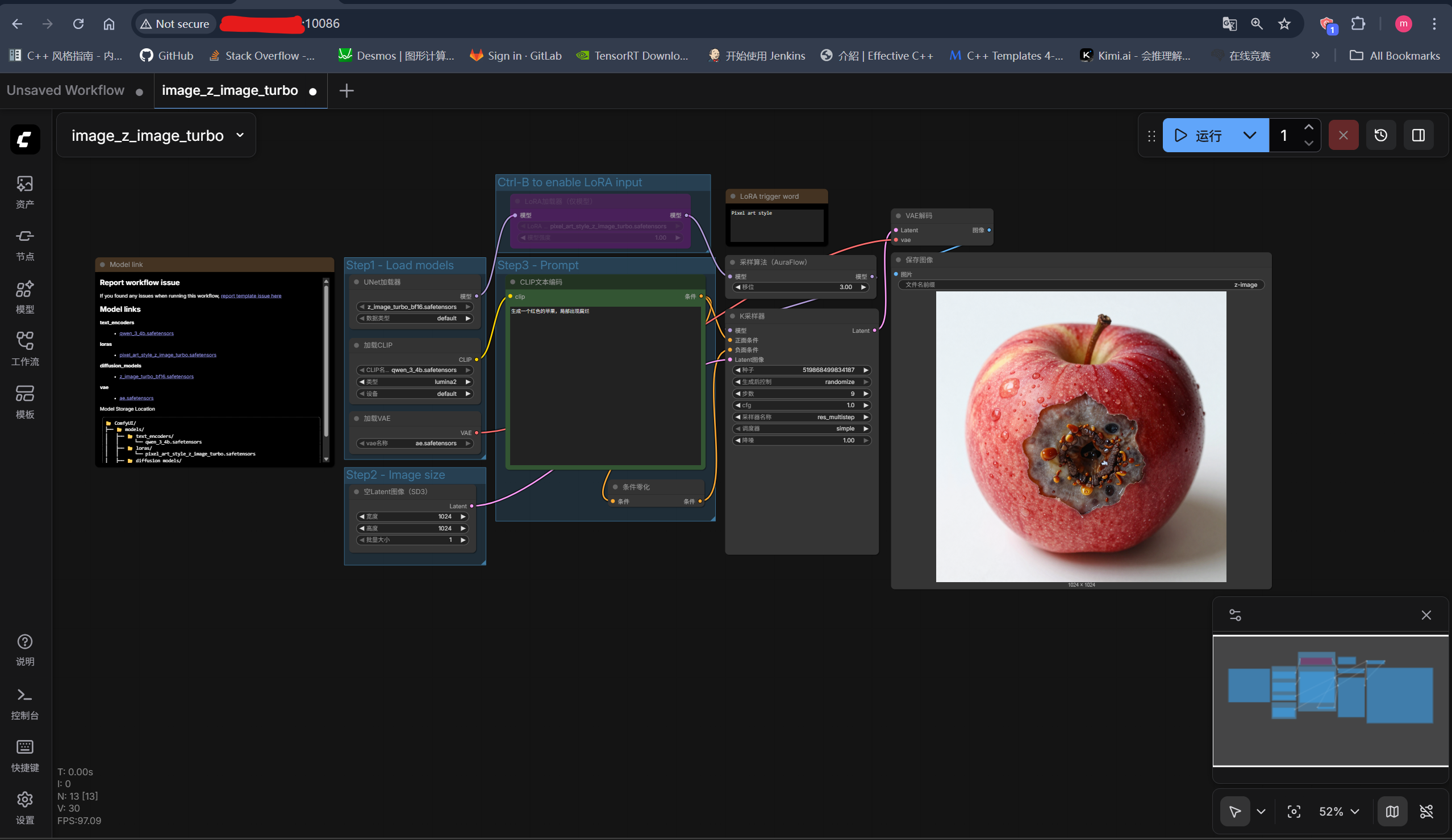
5.4 服务请求执行工作流
先看一下文档关于核心API路由介绍:ComfyUI-Server
| 路径 | get/post/ws | 用途 |
|---|---|---|
/ |
get | 加载 Comfy 网页 |
/ws |
websocket | 用于与服务器进行实时通信的 WebSocket 端点 |
/embeddings |
get | 获取可用的嵌入模型名称列表 |
/extensions |
get | 获取注册了 WEB_DIRECTORY 的扩展列表 |
/features |
get | 获取服务器功能和能力 |
/models |
get | 获取可用模型类型列表 |
/models/{folder} |
get | 获取特定文件夹中的模型 |
/workflow_templates |
get | 获取自定义节点模块及其关联模板工作流的映射 |
/upload/image |
post | 上传图片 |
/upload/mask |
post | 上传蒙版 |
/view |
get | 查看图片。更多选项请参见 server.py 中的 @routes.get("/view") |
/view_metadata/ |
get | 获取模型的元数据 |
/system_stats |
get | 获取系统信息(Python 版本、设备、显存等) |
/prompt |
get | 获取当前队列状态和执行信息 |
/prompt |
post | 提交提示到队列 |
/object_info |
get | 获取所有节点类型的详细信息 |
/object_info/{node_class} |
get | 获取特定节点类型的详细信息 |
/history |
get | 获取队列历史记录 |
/history/{prompt_id} |
get | 获取特定提示的队列历史记录 |
/history |
post | 清除历史记录或删除历史记录项 |
/queue |
get | 获取执行队列的当前状态 |
/queue |
post | 管理队列操作(清除待处理/运行中的任务) |
/interrupt |
post | 停止当前工作流执行 |
/free |
post | 通过卸载指定模型释放内存 |
/userdata |
get | 列出指定目录中的用户数据文件 |
/v2/userdata |
get | 增强版本,以结构化格式列出文件和目录 |
/userdata/{file} |
get | 获取特定的用户数据文件 |
/userdata/{file} |
post | 上传或更新用户数据文件 |
/userdata/{file} |
delete | 删除特定的用户数据文件 |
/userdata/{file}/move/{dest} |
post | 移动或重命名用户数据文件 |
/users |
get | 获取用户信息 |
/users |
post | 创建新用户(仅限多用户模式) |
对于文生图任务而言,需要三步来实现工作流调用:(1) 调用/prompt将工作流提交到队列;(2) 调用/history{prompt_id}获取当前任务的队列记录;(3) 调用/view获取对应结果。
具体操作步骤:
- (1)导出对应API配置:
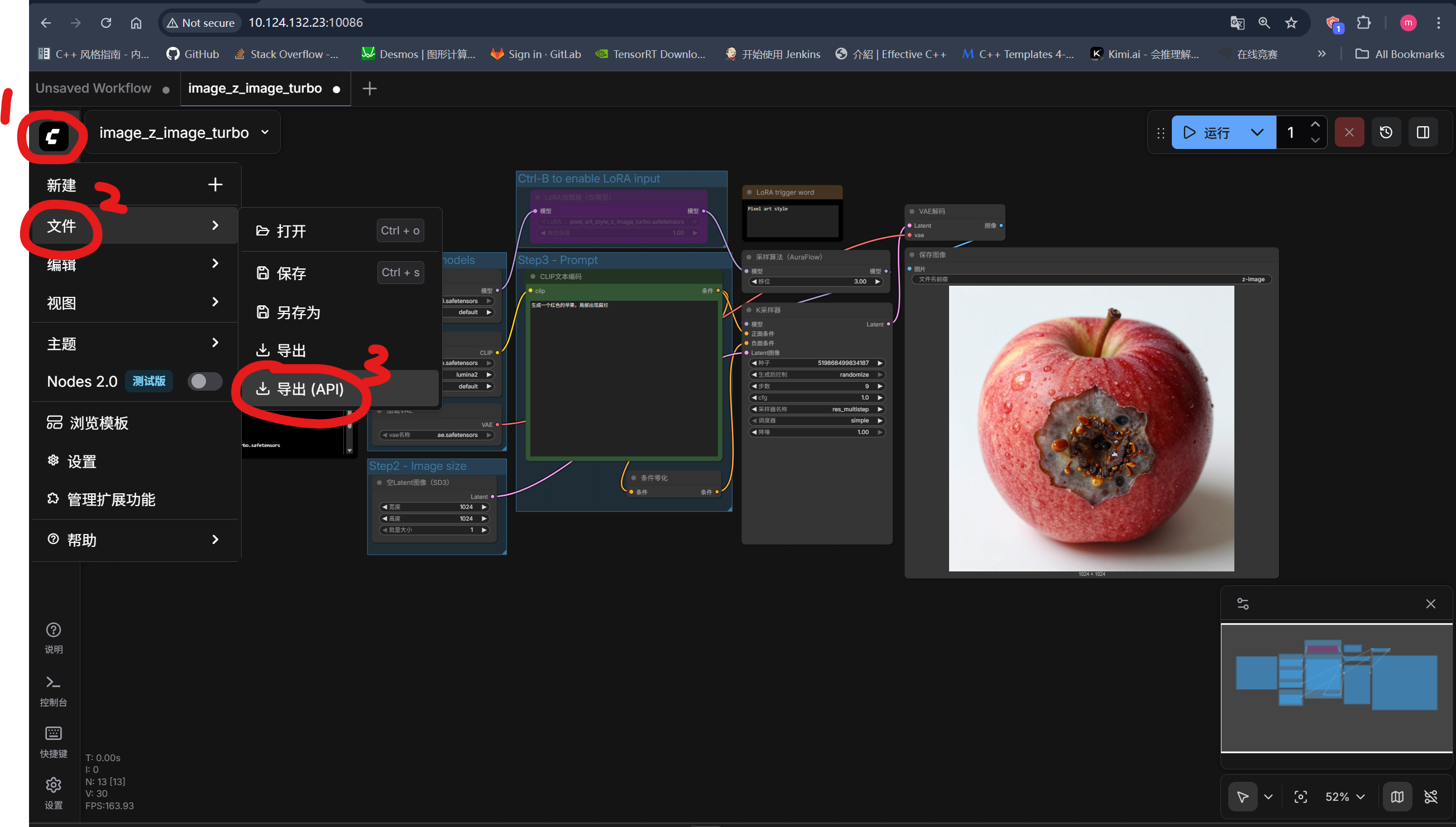
- (2)请求服务:
1 | ''' |
- (3)执行任务:
1 | >> python z_image.py |
- (4)生成结果:

参考资料
- [1] ComfyUI
- [2] ComfyUI-Server